







|
Darwin's Theory of Evolution by Natural Selection has long been analogized by those interested in the financial markets. From Andrew Lo’s “Adaptive Market Hypothesis” (an updated version of the efficient market hypothesis, derived from evolutionary principles) to Stephen Ross’s “Arbitrage Pricing Theory” (price changes are driven by arbitrage opportunities) the economic process of striking a bargain has been variously considered as an extension of the natural world. In this opinion piece, we give a view on how the evolving tools available to market participants are driving changes in the practices of those participants and we speculate what those evolutionary trends might look like. |
Market participants strive to use research and development (R&D) as the mechanism by which they attempt to consistently outperform the market. Renaissance Technologies Medallion fund has a long-run Sharpe ratio of 2.5 (post-cost) and is famously one of the most successful trading vehicles of all time. While such outperformance is not easy it is thus possible. The R&D tools used by the likes of Renaissance Technologies can be categorized into the following; data, compute and analytics. Further sub-categorizations are also possible, such as: data into price and non-price. Compute into different ASIC types, such as CPU and GPU. Analytics into ‘plumbing’ and ‘value-add’.
The financial markets are an information processing machine driven by data. In terms of R&D, historical data is used to learn and real-time data is used to infer. Barriers to entry on data access and consumption has long been a competitive advantage that many have sought to exploit with current legislation in the area widely deemed ineffective. Leading firms often boast about their data prowess; Two Sigma “we hold 22 PB of data” and Renaissance Technologies “We collect data that other people have never even thought about collecting”. While the 2017 estimated spend for ‘market data and analytics’ was $27 billion, increasing market fragmentation and complexity means the associated technical costs of collecting, collating and normalizing data is soaring. Some view this increased barrier to entry as having the opposite effect to the regulatory intention. While 25% of exchange revenues comes from market data the uncertainty over the future of the transaction fees revenue stream means exchanges are looking to increase their data revenues as well as diversifying by monetizing analytics and offering unstructured data sources through partnerships. Of the $27 billion market, around 30% is accounted for by Bloomberg and 30% by Reuters. When compared to other sectors, these frictions are high. In the B2C sector we have seen a variety of much reduced friction markets, for example Netflix (movies), Spotify (music), Deliveroo (food) and Uber (taxis). The driving force for these low-friction markets is the technology enabling cloud-hosted platforms.
The cloud as a managed service allows its users to do more; more quickly, cheaply and efficiently than before. Amazon cloud (AWS) launched in 2006, Google in 2008 and Microsoft in 2010. Competition between these three giants has kept prices low. As of 2018 we estimate AWS accounts for over 90% of the financial services spend on cloud, yet under 0.5% of financial services workflows currently use cloud. If the cloud is wonderful, why is the financial services uptake so low? Two important factors are the complexity and rate of change of the cloud. Complexity: the common analogy is that the cloud is like a water-tap – turn it on and water comes out which you pay for and then turn it off. No need to think about what is happening behind the scenes – the complexity is abstracted away. However, in the case of the cloud, it is not really a water-tap but the Hoover Dam; using that tap correctly is not only complex but difficult. It requires a team of people with rare and different skills, which are new to the traditional financial services sector. Secondly, the cloud is still a new technology and is still rapidly evolving. AWS added over 1,000 new features last year alone. Large beasts are not great when it comes to handling rapid change – if they get out competed their species must either evolve or die leading to the conclusion that such new scalable technologies favour small to mid-sized organizations.
|
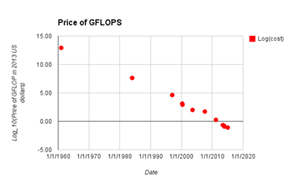
Price of GFLOPS in different years according to Wikipedia, adjusted to 2013 USD. Computing power per USD has increased by a factor of ten roughly every four years over the last quarter of a century. This coupled with the proliferation of sensors and the decreasing cost of data storage (USD/GB) (by a factor of ten roughly every four years) have caused significant changes in the way that the markets behave. Source: https://aiimpacts.org/trends-in-the-cost-of-computing/ and https://aiimpacts.org/costs-of-information-storage/
|
 |
For algorithmic participants (ie soon to be all participants), the paradigm in the age of cloud-computing is that learning takes place on the cloud (cheap compute and storage, high-latency) and inference takes place at the colo (expensive compute and storage, low-latency). It is worth noting this is a paradigm faced by a multitude of industry sectors, not just finance. This leads to a tricky problem, how to interface the two environments? The traditional approach when having research and production in-house/on-prem was to be able to move between them at the flick of a switch. One trend in this space is the cloud providers moving towards edge locations, reducing latencies while trying to minimize the associated computational disadvantages. However, the final constraint we all must obey in this space is the speed of light.
A user selects the compute core type based on their workload - three main types are offered by the cloud providers: CPUs which were designed for office apps but evolved for string search. GPUs which were designed for graphics but evolved for dense linear algebra. TPUs are being designed for machine intelligence, specifically for sparse matrix algebra (more representative of real-life data). AWS does not yet offer a TPU while Google is on its second iteration already. FPGAs are a type of programmable core suitable for doing a large number of identical operations quickly, such as Monte Carlo option pricing or limit order book rebuilding. However, it is GPUs which have been in the limelight for the last couple of years, with demand far out-stripping supply; driven partly by gaming, partly by the phenomena of bitcoin mining and partly by the equally emotive topic of deep-learning.
The ability to generate alpha through machine learning is the pinnacle of many market participant’s dreams. The well-publicised and impressive achievements of Deepmind have led to deep-learning and reinforcement-learning attracting scores of interested companies keen to exploit the advances in this science. Unfortunately for these interested parties it is a long and difficult road from point of interest to getting intellectual property working in production. Open-source libraries like TensorFlow, OpenAi Gym and Horovod undoubtedly make the process easier, however interfacing the data with the hardware, the open-source library and the participants own IP is not only difficult, it is expensive and time consuming.
Deep-learning, a now so fashionable statistics methodology, was in the 1990’s deemed very unfashionable. Three things happened which changed that; firstly, large amounts of computing power, especially GPUs, became available enabling large amounts of data to be crunched. Secondly, large amounts of labelled data became available giving the statistics underpinning the technique a chance to work. Thirdly, scientists modified their old networks to use multiple ‘hidden-layers’ enabling the use of the word “deep”. These events then coincided with the advent of the public cloud. The venture-capital firm Andreessen Horowitz described this as “deep learning’s Cambrian explosion” the analogy being to the geological era when most higher animal species suddenly burst onto the scene. However, for those that are hopeful that deep-learning is a silver bullet there may be bad news; all the scientifically credible success stories of deep-learning to date have been on high signal-to-noise datasets (cat pictures for example). Financial data is notoriously noisy – the chances are deep-learning will have to evolve still further to be able to offer real value-add to financial practitioners who wish to exploit it.
|
We are all currently living through a scientific revolution – the information age. Stemming from Shannon in the 1950’s this step-change in how information is collected, stored, analysed and used is having profound effects on all our lives, including financial market participants. Our belief is that the R&D tools used will not only themselves continue to evolve, but that their use will in-turn cause the market and its behaviour to evolve. The Homo sapien participants of tomorrow who will survive are those that are aware of the rate of tool evolution and are able to make predictions as to its nature. For our part, we see the evolutionary trends as being out-sourcing, managed solutions, identification and decomposition of services into plumbing and value-add, ability to use information across the spectra of the frequency domain, an ever decreasing R&D OODA loop from idea-generation to realized-return and finally the ability to exploit new technological tools more quickly than the neighbouring Saber-Toothed tiger. |
To find out more, visit our website https://bmlltech.com .

